


If your brand “doesn’t show up” in AI answers, it’s almost never for a single reason.
It’s usually a combination of access (can they read you?), eligibility (are you indexable and trustworthy?), and citability (are you easy to extract and verify?).
What are “authority signals” for LLMs?
In practice, authority signals are signals that help an answer engine (ChatGPT Search, Perplexity, Google AI Overviews/AI Mode, etc.) decide whether your page is a reliable source and citable for a question.
Key idea: many systems combine document retrieval (search/retrieval) with generation (LLM). That pattern (RAG-like) has existed in research and products for years: first retrieve relevant passages, then write with those sources.
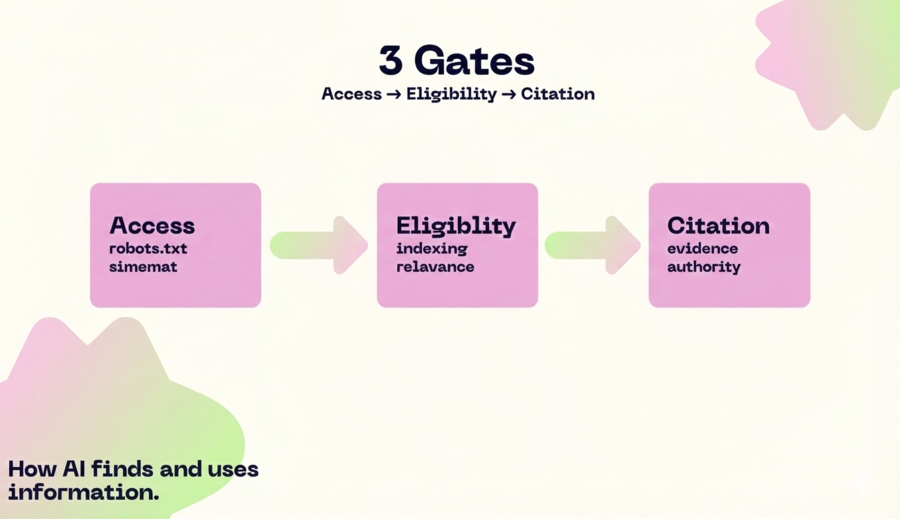
How do LLMs decide which source to cite?
Think in 3 “gates”:
- Access: bots and systems can crawl/retrieve your content.
- Eligibility: your page can be indexed and shown “with snippets”, and isn’t blocked by policies or technical issues.
- Selection for citation: your content has the best combination of relevance + clarity + evidence + reputation for that question.
For Google, the official “AI features and your website” documentation says there are no special requirements to appear in AI Overviews/AI Mode beyond being indexable and following standard SEO best practices and technical requirements.
Gate 1: Access (robots, bots, and permissions)
Before talking about “authority,” confirm that the right agents can read you.
1) OpenAI: difference between search and training
OpenAI documents two key bots:
- OAI-SearchBot (to appear in ChatGPT search results).
- GPTBot (related to crawling for foundation model training).
If you block OAI-SearchBot, you may be excluding yourself from visibility in ChatGPT’s search experiences.
2) Perplexity: results crawler with citations
Perplexity explains that webmasters can control crawling with robots.txt and that PerplexityBot gathers and indexes information for search experiences.
And Perplexity’s Help Center states that answers include numbered citations linking to original sources.
3) Anthropic: three agents (training, user, search)
Anthropic details ClaudeBot (potential training), Claude-User (user-requested retrieval), and Claude-SearchBot (improving search results) and explains what happens if you disable each one.
4) Google-Extended: no separate HTTP UA
Google states that Google-Extended doesn’t have a separate HTTP user-agent string; crawling happens with existing Google user agents, and the robots.txt token is used for control. (Google for Developers)
robots.txt template (illustrative)
Note: this is an example. Adjust paths based on public/private content and your legal strategy.
User-agent: OAI-SearchBot
Allow: /
User-agent: PerplexityBot
Allow: /
User-agent: Claude-User
Allow: /
User-agent: Claude-SearchBot
Allow: /
User-agent: GPTBot
Disallow: /private/
User-agent: Google-Extended
Allow: /
Gate 2: Eligibility (indexation, policies, and being “showable”)
This is where many sites look good but fail basic filters.
- Meet anti-spam policies: if you’re doing gray tactics, visibility drops (in SERPs and, by extension, AI surfaces that rely on indexes and quality signals).
- Helpful, people-first content: Google frames this as foundational for prioritizing reliable information.
- Clean structure + consistent structured data: Google’s structured data guidelines emphasize not blocking pages with markup and ensuring markup reflects what’s visible to users.
We tested blocking “old blog folders” to “clean up” crawl → half of our citable content disappeared from AI answers → we reopened crawling, consolidated with canonicals, and improved snippets → visibility stabilized and long-tail traffic returned.
— Pablo López, Tacmind
Gate 3: Being “citable” (clarity, evidence, and extraction)
These are the authority signals that most often move the needle:
- Direct answer + definition in the first third of the page (no fluff).
- Consistent entities: same product/category/brand names, acronyms, and relationships (“X is a type of Y”, “X includes A/B/C”).
- Verifiable evidence: primary sources, dates, methodology, limitations.
- Extractable formatting: clear headings, lists, steps, simple tables (not “buried blocks”).
- External reputation: mentions/corroboration from relevant third parties (not just backlinks by volume).

Tacmind framework: Authority LAYERS (for LLMs)
I use this framework when auditing why a brand isn’t showing up as a source.
C — Crawl & access
- robots.txt and WAF/CDN don’t block relevant bots
- key pages are accessible without heavy rendering (or have SSR)
A — Authorship & editorial accountability
- visible author + bio + “about”
- trust pages (contact, editorial, corrections) where relevant
P — Proof (evidence)
- primary sources linked
- numbers with dates and context
- “what it includes / what it doesn’t” (reduces ambiguity)
A — Semantic alignment (entities + architecture)
- topic clusters and internal linking
- pillar page + supporting pages
- consistent terminology
S — External signals (corroboration)
- profiles and mentions on industry reference sites
- repositories, directories, papers, associations, press (as applicable)
If you want to go deeper on “how to write so you get cited,” here are two Tacmind guides we use as production baselines:
- Content for LLMs: how to write for generative & answer engines
- LLM SEO Blueprint (structure + signals)
We tested “more content” without changing structure → AI kept citing competitors → we rewrote definitions, added primary sources, and a “limits” block → citations started appearing in comparative prompts (“best X for Y”).
— Pablo López, Tacmind
Prioritization method: A-Score (Impact × Coverage × Confidence ÷ Effort)
To avoid spreading yourself thin, score each initiative with:
- Impact (1–5): how much it could increase citations/visibility.
- Coverage (1–5): how many engines it affects (ChatGPT/Perplexity/Google/Claude).
- Confidence (1–5): how likely it is to work (based on evidence and control).
- Effort (1–5): time/resources.
A-Score = (Impact × Coverage × Confidence) ÷ Effort
Start with the highest scores.
30-day plan to improve your authority signals (without burning out)
Days 1–7: Access + eligibility
- Audit robots.txt + CDN/WAF blocks (search bots and user-initiated retrieval).
- Fix noindex/canonicals on pages you want cited.
- Review basics: thin content, template abuse, duplicate content.
Useful reference for people-first quality: Creating helpful, reliable, people-first content
Days 8–14: Citability (structure and extraction)
- Rewrite 5–10 target pages with:
- clear definition
- bullets
- steps/checklists
- “limits / assumptions” section
- Make sure key info is in text (not only in JS tabs or images).
Days 15–21: Evidence + entities
- Add primary sources and dates to important claims.
- Entity standard (names, synonyms, attributes).
- Strengthen internal linking (pillar → supporting).
Complementary guide: Generative Engine Optimization (GEO) in 2026
Days 22–30: External signals + measurement
- Pick 3 “places” where your category is validated (directories, docs, comparisons, associations).
- Publish/update profiles and mentions consistent with your entity.
- Define your prompt set and re-measure weekly.
If you want to measure and prioritize this with a ready dashboard, see Tacmind Pricing or request a demo.
We tried “optimize for AI” only with prompts → without fixing indexability and snippet eligibility → nothing changed → we fixed access + pillar pages + evidence → we started seeing consistent mentions and fewer brand errors.
— Pablo López, Tacmind
Common mistakes (and quick fixes)
- Accidentally blocking bots (robots.txt / WAF)
- Fix: check logs + rules. Ensure search/user-initiated bots are allowed.
- Pretty content, but hard to extract (only long paragraphs)
- Fix: add definitions, bullets, steps, “what it includes/doesn’t include”.
- Claims without dates or sources
- Fix: every important number should have a source + context + date.
- Inconsistent entities (product name changes across pages)
- Fix: entity glossary and a review of headings/anchors/internal links.
- Heavy JS that hides real content
- Fix: SSR or at least render critical content in HTML.
- Schema disconnected from visible text
- Fix: align markup with what the user sees (and follow policies).
- Cannibalization (10 URLs answering “the same thing”)
- Fix: consolidate, canonicalize, define one “source” URL.
- Not measuring with real prompts
- Fix: a question set per cluster (“best X”, “alternative to”, “pricing”, “how to”).
FAQ
Is “authority signals for LLMs” the same as E-E-A-T?
They overlap, but they’re not identical. In AI, citability (structure + evidence + extraction) matters a lot, in addition to reputation and quality.
Do I need special files to appear in Google AI Overviews?
Google states there are no special requirements beyond standard technical requirements and SEO best practices for inclusion in AI features.
So… does llms.txt work or not?
It can help in some agent workflows and “LLM-friendly” consumption (it’s a community proposal), but it doesn’t replace technical SEO, indexation, structure, and evidence. If you’re curious, start with the spec: llms.txt standard and then cross-check with this guide about llms.txt on Tacmind.
What matters more: backlinks or structure?
To get cited, structure and evidence are often the fastest unlock. External signals help, but if your content isn’t extractable/verifiable, you still lose.
Does Perplexity actually cite sources?
Yes: Perplexity’s Help Center says answers include numbered citations linking to original sources.
How do I measure this without vanity metrics?
Measure by prompts, citation presence, and attribute accuracy (name, category, claims). If consistency rises and errors drop, you’re building real authority.
Was this helpful?



